

Imagine you're building something with LEGOs instead of a fixed, pre-molded model kit. That’s the heart of scalable system architecture—it’s about designing systems with the flexibility to grow and adapt, easily handling more users, more data, and more traffic without breaking a sweat. Getting this right from the start is what separates a business that thrives from one that crashes under its own success.
Building Systems That Grow With You
At its core, a scalable system architecture is simply a plan for building software and its underlying infrastructure so they can handle a bigger workload.
Think about the difference between a small, local coffee shop and a global chain like Starbucks. The local shop might have one amazing, high-end espresso machine that does everything. If a huge morning rush hits, their only option is to upgrade that single machine to a faster, more powerful model. This is called vertical scaling, or "scaling up." You're adding more power (like CPU or RAM) to an existing server. It's a quick fix, but you'll eventually hit a hard limit—you can only make one machine so powerful.
The global chain, however, doesn't depend on a single, giant super-machine. Instead, it opens new stores, each with its own standard set of equipment. This is horizontal scaling, or "scaling out"—you add more machines to your network to distribute the work. Modern scalable systems almost always favor this approach because the potential for growth is virtually unlimited, and it’s far more resilient. If one store has an issue, customers can just go to the next one down the street.
To help you see the differences more clearly, here's a quick breakdown of the two approaches.
Horizontal vs Vertical Scaling at a Glance
| Attribute | Horizontal Scaling (Scaling Out) | Vertical Scaling (Scaling Up) |
|---|---|---|
| Method | Add more machines (servers) to the system | Add more resources (CPU, RAM) to a single machine |
| Growth Limit | Virtually limitless; add as many machines as needed | Capped by the maximum hardware capacity of a single server |
| Resilience | High; failure of one machine doesn't take down the system | Low; creates a single point of failure |
| Complexity | Higher; requires load balancing and distributed logic | Lower; simpler to implement initially |
| Cost | Can be more cost-effective with commodity hardware | Can become very expensive for high-end hardware |
As you can see, while vertical scaling has its place for simple, predictable growth, horizontal scaling is where true, long-term resilience and flexibility lie.
Monolithic vs. Microservices Architectures
How you structure your application itself has a massive impact on how well it can scale. This is where the debate between monolithic and microservices architectures comes in.
A monolithic architecture is like that single, all-in-one espresso machine. Every function—taking orders, grinding beans, frothing milk—is bundled together into one large, tightly coupled application. They're often simpler to build and deploy at first. But when you need to scale, you have to scale the entire application, even if only one small part of it is under heavy load. It's incredibly inefficient.
In stark contrast, a microservices architecture is like the global coffee chain with specialized stations. The system is broken down into a collection of small, independent services, where each one handles a specific job—one service for payment processing, another for user profiles, another for inventory. If the payment service gets overwhelmed during a holiday sale, you can simply add more instances of that specific service without touching anything else. This granular control is a key reason why it's a pillar of modern scalable design.
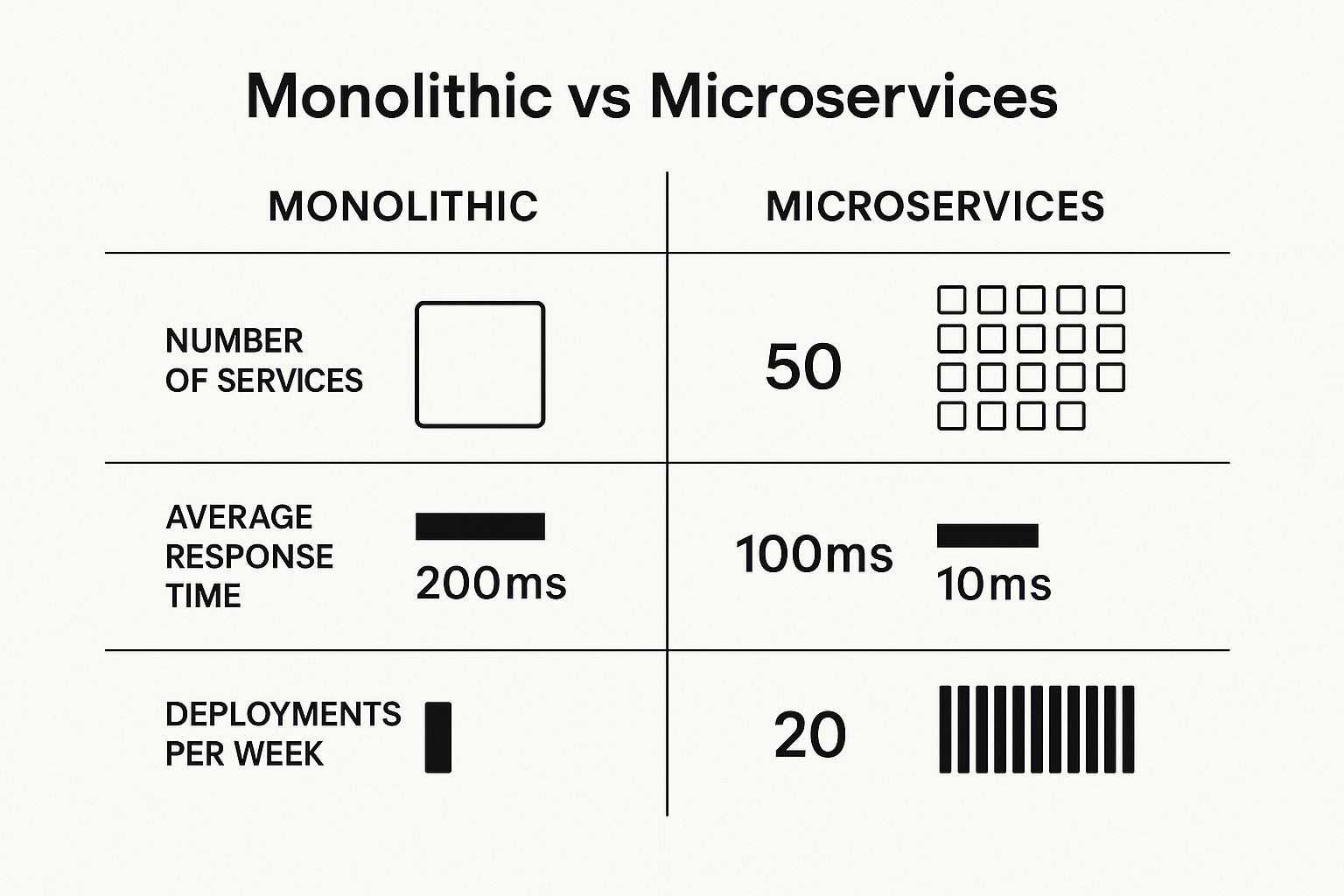
The data here speaks for itself. Breaking a large application into smaller, focused services can slash response times in half and allow teams to deploy updates far more frequently, creating a much more agile and responsive system.
The Importance of Strategic Scaling
Choosing your scaling strategy isn't just a technical detail—it's a critical business decision. Vertical scaling can be a good starting point for predictable, moderate growth because it’s often simpler to manage. The problem is, it introduces a single point of failure and always has a physical ceiling.
A system that relies solely on vertical scaling will eventually hit a wall. True, long-term scalability is achieved by designing for horizontal distribution from the outset, ensuring the system can expand indefinitely to meet future demand.
Ultimately, a thoughtfully designed scalable architecture gives you the power to handle sudden traffic spikes, support sustainable growth, and innovate without fear. By understanding these core ideas, you can build applications that thrive under pressure instead of buckling when you need them most.
Core Principles for Designing Scalable Systems

Building a truly scalable system architecture isn't just about throwing more servers at a problem. It’s a way of thinking, a commitment to a few core design principles that form the invisible foundation of a system that can grow without breaking a sweat.
Think about a busy restaurant kitchen. You don't have one chef frantically trying to cook every single dish. Instead, you have specialized stations—one for grilling, another for salads, and a separate one for desserts. This is exactly how we approach decoupling in system design.
Embrace Decoupling and Modularity
Decoupling is all about designing your system’s components to be independent. If the dessert station runs out of chocolate, it doesn't bring the grill line to a grinding halt. In the software world, this means a glitch in your user login service won't crash the product search feature.
This modular approach gives you incredible flexibility. When the grill station gets slammed with orders, you can add another cook just for that station without bothering the salad prep team. Likewise, if your payment processing service is getting hammered, you can scale that one specific component. It's this kind of targeted efficiency that defines a robust, scalable system.
Design for Statelessness
Another critical principle is statelessness. A stateless application doesn’t remember anything about a user's session on the server itself. Picture a modern call center where any agent can help you because they all have access to the same customer database. You're not stuck waiting for the one specific person you talked to last week.
A stateless design simplifies everything. It allows a load balancer to send your request to any available server, because every server has what it needs to handle the job independently. This cuts down on complexity and makes scaling out horizontally a breeze.
When an application is "stateful," it’s like being forced to talk to that one specific agent every time. If they're busy or on break, you’re out of luck. This creates bottlenecks and single points of failure—the sworn enemies of scalability.
Implement Asynchronous Communication
Finally, let's look at how the different parts of your system talk to each other. Instead of one service waiting around for another to finish its task (synchronous communication), a scalable design often relies on asynchronous communication.
It’s like a restaurant using a ticket system. A waiter places an order on the rail, and the kitchen grabs it when they're ready. The waiter doesn't have to stand there watching the chefs cook; they're free to go take another table's order. This workflow, often managed by tools like message queues, creates a buffer that smoothes out traffic spikes and keeps individual services from getting overwhelmed.
As you weigh these design decisions, it's also smart to keep an eye on the future. You can get a better sense of where things are headed by looking into key IT support trends for 2025. By weaving these principles into your architecture, you build a system that's not just bigger, but smarter and far more resilient.
Essential Patterns for Building Scalable Systems

While design principles give us the "why" behind a scalable system architecture, it's the architectural patterns that show us the "how." Think of these as proven, field-tested blueprints for structuring your applications to handle growth without breaking a sweat. This is where we move from abstract theory to practical, real-world implementation.
Two of the most powerful patterns for scalability are Microservices and Command Query Responsibility Segregation (CQRS). Though they tackle different challenges, they both hinge on a core idea: break down big, complex problems into smaller, manageable pieces that can be scaled on their own.
The Microservices Pattern
The Microservices pattern is essentially decoupling brought to life. Instead of building one giant, all-in-one application (a monolith), you create a collection of small, independent services. Each service is built around a specific business function—like user authentication, the product catalog, or payment processing.
This approach brings some huge advantages when it's time to scale:
- Targeted Scaling: If your product catalog gets a massive surge of holiday traffic, you can beef up just the catalog service without touching anything else. It's precise and efficient.
- Technology Freedom: Different teams can use different technologies for their services. You can pick the absolute best tool for each specific job instead of being locked into one tech stack.
- Faster Development Cycles: Small, focused teams can work on their individual services at the same time, which means quicker updates and feature rollouts.
Imagine shifting from a single, enormous factory that does everything to a network of specialized workshops. Each workshop runs on its own, making the entire system far more flexible, resilient, and efficient.
The CQRS Pattern for High Throughput
For systems that have to juggle a high volume of both reads and writes, the Command Query Responsibility Segregation (CQRS) pattern is a total game-changer. The idea is simple but incredibly powerful: you separate the models you use to update information (Commands) from the models you use to read it (Queries).
In most applications, the way you look at data is very different from how you change it. For example, a user checking their bank account balance is a simple read. A transaction, on the other hand, is a complex write operation involving multiple validation steps and database updates. CQRS recognizes this split by creating separate, optimized paths for each type of operation.
By separating read and write operations, CQRS allows each side to be scaled independently based on its specific load. You can optimize the read database for fast queries and the write database for transactional consistency, avoiding performance bottlenecks.
This pattern has had a massive impact, especially in high-transaction fields like finance. The adoption of scalable architectures has completely changed how enterprises handle their transactional workloads. For instance, one major banking client used the CQRS pattern to process 5,000 transactions per second, creating specialized read models for things like account balances and transaction histories. This architectural shift led to a twelve-fold increase in transaction throughput while keeping performance rock-solid. You can dig into more details about these scalable architecture patterns by exploring further case studies.
By putting patterns like Microservices and CQRS into practice, you build a solid foundation for a system that doesn't just survive growth—it thrives on it.
The Modern Tech Stack for Scalable Architecture
If architectural principles and patterns are the blueprint, then your technology stack is the collection of power tools and heavy machinery that actually brings your scalable system to life. You can have the best plans in the world, but without the right tools, you're just connecting theory to practice with duct tape and wishful thinking.
Modern tech stacks are built from the ground up with components designed for distribution, automation, and resilience. These aren't just optional add-ons; they are the very engine of scalability. For any business needing to process huge datasets, the right framework is simply non-negotiable.
Powering Scale with Automation and Distribution
A huge shift in modern architecture has been the move toward automation. Tools that handle deployment, scaling, and daily operational tasks cut down on manual work and, more importantly, minimize human error. This allows a system to react to changing demands in real time, which is where containerization and orchestration have become the gold standard.
Containerization, with tools like Docker, is all about packaging an application and all its dependencies into a single, neat, portable unit. Think of it like a standardized shipping container; it runs exactly the same way everywhere, whether that's on a developer's laptop or across a massive cloud environment.
Orchestration platforms like Kubernetes then step in to act as the port authority for all these containers. Kubernetes automatically manages their deployment, scaling, and networking, making sure the entire system runs smoothly and efficiently, even when you have thousands of moving parts. To get these services running in the first place, selecting from affordable web hosting solutions for businesses is a critical first step to build on a solid foundation.
The combination of Docker and Kubernetes forms the backbone of most modern scalable applications. It provides the agility and automated control needed to manage complex, distributed systems effectively, allowing engineers to focus on building features instead of managing infrastructure.
Adopting these technologies isn't a small change—it's a game-changer. An analysis from NILG.AI projects that by 2025, distributed computing frameworks like Apache Spark will be fundamental for any system that routinely handles petabytes of data.
The report also found that over 90% of large enterprises are already using containerization and orchestration tools like Docker and Kubernetes. Organizations that adopt this stack report up to a 50% reduction in manual deployment overhead and a 30% increase in infrastructure efficiency. This just goes to show how critical the right tech is for building systems that can truly perform under pressure. You can dive deeper into these findings on data science architecture and what they mean for the industry.
Solving for Data Scalability and System Resilience
A sophisticated application is only as scalable as its weakest link. More often than not, that weak link is the database. Your system's capacity to handle more users, more requests, and more activity is directly tied to how well it manages the data flowing through it.
We're living in a world on track to generate 180 zettabytes of data annually by 2025. In this reality, a traditional, single-server database just can't keep up. It quickly becomes a bottleneck, leading to slow queries, frustrating timeouts, and a terrible user experience.
This data explosion is a critical challenge for any growing system. When a centralized database gets slammed with heavy traffic, it struggles. That’s why modern data architecture has shifted its focus to distributed storage and specialized databases built from the ground up for horizontal scaling.
Moving Beyond the Traditional Database
To break free from the limitations of a single, overburdened server, today’s architects favor solutions built for distribution. Instead of pouring more resources into one massive server (vertical scaling), they spread the data across a fleet of multiple, more modest machines. This approach is at the heart of NoSQL databases, which offer some game-changing advantages:
- NoSQL Databases: Tools like Cassandra and MongoDB are engineered to scale horizontally across hundreds or even thousands of commodity servers. They are masters at handling massive volumes of unstructured data and high-speed transactions, making them a perfect fit for modern web and mobile apps.
- Distributed Storage: This method chops up large datasets into smaller, manageable chunks and stores them across a network of machines. This doesn't just boost performance by enabling parallel processing—it also builds in resilience. If one machine (or node) fails, the whole system doesn't come crashing down with it.
These technologies are the bedrock for building systems that can process millions of transactions without breaking a sweat. It's a core requirement for almost any serious enterprise application. For instance, the same principles of managing complex, distributed data are vital when implementing large-scale systems, a topic we cover in our guide to ERP software solutions.
Why Resilience Is Non-Negotiable
Data scalability on its own isn’t the full picture; your system must also be resilient. A resilient system is designed to expect and withstand failure, ensuring it stays available and functional even when individual parts go offline. This could mean replicating data across different geographic regions or having automated failover mechanisms that instantly reroute traffic away from a failing server.
Designing for failure is not pessimistic—it's pragmatic. A truly scalable system architecture assumes that components will fail and includes mechanisms to recover gracefully with minimal impact on the end-user.
This proactive mindset is crucial because the stakes are incredibly high. According to insights from Acceldata and Gartner, a staggering 85% of big data analytics projects fail to deliver on their goals. A huge reason for this is poor planning for both scalability and resilience. You can dive deeper into this by reading about designing future-ready platforms to grasp the full scope of the challenge.
Ultimately, weaving data scalability and system resilience into your architecture from day one isn't just a "nice-to-have." It’s essential for survival.
Of course. Here is the rewritten section, crafted to sound like an experienced human expert, following all your specified requirements.
Frequently Asked Questions About Scalable Architecture
Even when you've got a handle on the principles, putting scalable architecture into practice brings up a whole new set of questions. Let's tackle some of the common "what ifs" and "when should I" moments that pop up when you move from the whiteboard to the real world.
When Should I Start Thinking About Scalable Architecture?
From day one. Seriously. Even if you're just sketching out a tiny project or a minimum viable product (MVP), you need to have scalability in the back of your mind.
Now, that doesn't mean you need to build an infrastructure for millions of users right out of the gate. That would be overkill. But making smart, simple choices early on—like building your services to be stateless or thinking in a modular way—will pay massive dividends down the road. It’s like pouring a solid foundation before building a house. It's infinitely easier to get it right the first time than to jack up the whole structure later to fix it.
Is a Microservices Architecture Always the Best Choice?
Absolutely not. While a microservices pattern offers incredible flexibility and lets you scale specific parts of your application, it's not a silver bullet. Its biggest downside? A massive jump in operational complexity.
Suddenly, you're juggling deployments, monitoring, and communication across dozens of services, all while trying to keep data consistent. That takes a ton of expertise and the right tooling. For smaller apps, new projects, or teams without a dedicated DevOps crew, a well-structured monolith can be a much more practical choice. It's simpler to build, test, and deploy, and you can easily scale it vertically to handle your initial growth. The right answer really comes down to your project, your team's skills, and your vision for the future.
How Do You Measure if a System Is Scalable?
Scalability isn’t just a feeling—it’s something you can and should measure with cold, hard data. A system is truly scalable if its performance holds up as you add more resources to handle more work. Put simply, if you double the traffic and double your server capacity, your users shouldn't notice a difference.
To prove this, you need to run performance tests and keep a close eye on key metrics as you crank up the load. The most important ones to watch are:
- Latency: How long does a request take to complete? In a scalable system, this number stays stable even as traffic skyrockets.
- Throughput: How many requests can your system handle per second (RPS)? This should climb in a straight line as you add more resources.
- Error Rate: What percentage of requests are failing? This should stay consistently low, not spike when things get busy.
- Resource Utilization: Watching your CPU, memory, and network usage helps you spot bottlenecks and make sure your new resources are actually being put to good use.
At KP Infotech, we specialize in building robust, scalable digital solutions that grow with your business. From high-performance websites and mobile apps to custom enterprise software, we lay the architectural foundation for long-term success. Discover how our development services can help you build for the future.
