

A well-designed database is the foundational blueprint for any successful application. It is the critical infrastructure that determines whether a system can scale efficiently or will buckle under the weight of its own data. The distinction between a robust, high-performance database and a fragile, slow one often comes down to a core set of strategic principles applied during the initial design phase. Overlooking these fundamentals is a common but costly mistake, leading to sluggish performance, frustrating data anomalies, and significant maintenance burdens that stifle innovation.
This guide moves beyond generic advice to provide a comprehensive roundup of 8 essential database design best practices. We will explore practical techniques that are non-negotiable for building modern, resilient data architectures. You will learn not just the "what" but the "why" behind each principle, from the logical clarity of normalization to the performance gains of a smart indexing strategy.
Each section is designed to be actionable, offering clear implementation details and real-world scenarios. We will cover:
- Database Normalization: Structuring data to reduce redundancy.
- Proper Indexing: Accelerating data retrieval operations.
- Consistent Naming Conventions: Improving schema readability and maintenance.
- Data Type Optimization: Using resources efficiently and ensuring integrity.
- Referential Integrity: Maintaining logical consistency between tables.
- Documentation and Versioning: Tracking schema evolution.
- Security Best Practices: Safeguarding your most valuable asset.
- Performance and Query Design: Writing efficient queries from the start.
By mastering these techniques, you will be equipped to build databases that are not only fast and secure but also flexible enough to evolve with your business needs.
1. Database Normalization
Database normalization is a foundational technique in relational database design. It's the process of organizing the columns (attributes) and tables (relations) of a database to minimize data redundancy and improve data integrity. By breaking down large, complex tables into smaller, more manageable ones and defining clear relationships between them, normalization prevents data anomalies that can occur during data insertion, updates, or deletion. This structured approach is a cornerstone of effective database design best practices.
The process follows a series of guidelines known as normal forms. While several exist, the first three are the most critical for practical application. Each normal form represents a progressively stricter set of rules to eliminate redundancy and undesirable dependencies. Achieving a normalized state ensures that each piece of data is stored in only one place, making the database more efficient, scalable, and easier to maintain.
Why It's a Best Practice
A normalized database is predictable and logically clean. For instance, in an e-commerce system, customer information, orders, and product details should not be crammed into a single table. Instead, normalization dictates creating separate Customers, Orders, and Products tables. This separation means a customer's address only needs to be updated in one place (the Customers table), preventing inconsistencies across multiple order records.
Key Insight: Normalization is not just about saving storage space; it's about safeguarding data integrity. It ensures that relationships between data are clear and enforced, which is crucial for building reliable and robust applications.
Actionable Tips for Implementation
To apply normalization effectively, follow these guidelines:
- Target the Third Normal Form (3NF): For most applications, 3NF provides an excellent balance between data integrity and performance. It eliminates most common data anomalies without the complexity of higher normal forms.
- Use Foreign Keys: Implement foreign keys to enforce referential integrity between related tables. This ensures that a record cannot be added to a child table (like
Orders) unless a corresponding record exists in the parent table (likeCustomers). - Consider Denormalization Strategically: For applications that are extremely read-heavy, like analytics dashboards or reporting systems, a fully normalized database can sometimes lead to slow performance due to the need for complex joins. In these specific cases, intentionally denormalizing some data (duplicating it) can improve query speed. This should be a conscious, documented decision, not an accident.
This concept map illustrates the progressive journey through the first three normal forms.
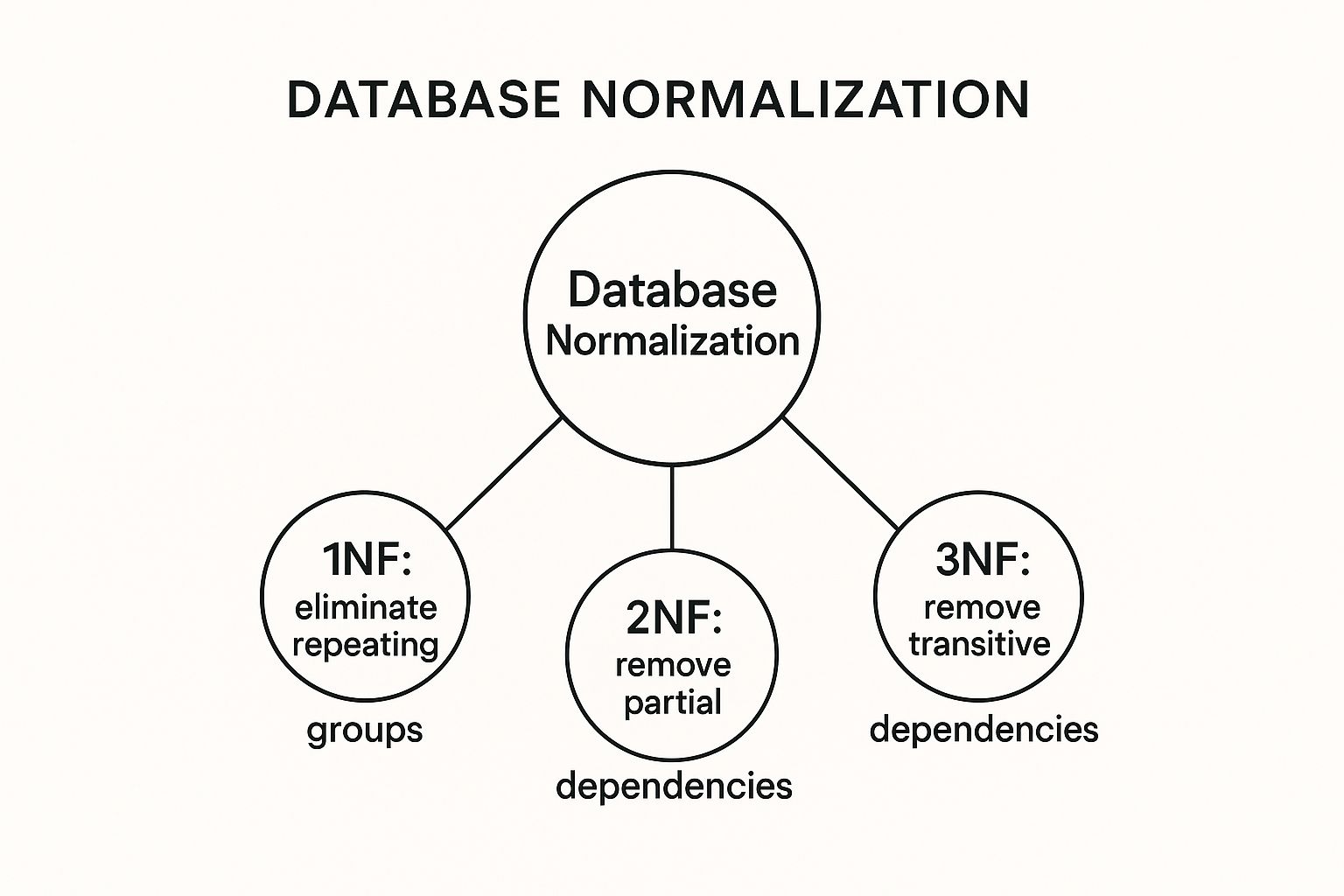
The visualization shows how each normal form builds upon the last, systematically removing different types of data dependencies to achieve a well-structured database.
2. Proper Indexing Strategy
A proper indexing strategy is a critical performance-tuning technique in database management. Indexes are special lookup tables that the database search engine can use to speed up data retrieval. Much like the index in a book helps you find a topic without reading every page, a database index helps find data quickly without scanning every row in a table. Implementing a well-thought-out indexing plan is a core component of database design best practices, as it directly impacts application responsiveness and user experience.
An effective strategy involves more than just creating indexes; it requires a careful balance. While indexes significantly accelerate read operations (like SELECT queries), they incur a cost. Each index consumes storage space and adds overhead to write operations (INSERT, UPDATE, DELETE), as the index must be updated along with the data. Therefore, the goal is to create the right types of indexes on the most appropriate columns to maximize query performance while minimizing this overhead.

Why It's a Best Practice
Without proper indexes, a database must perform a "full table scan" for many queries, meaning it reads every single row to find the ones that match the query's criteria. On large tables, this is incredibly inefficient and slow. For example, an e-commerce platform like Amazon relies heavily on indexing to power its product search. A compound index on columns like category, price, and rating allows the system to instantly filter millions of products to return relevant results to the user.
Key Insight: Indexing transforms data retrieval from a brute-force search into a highly efficient lookup. It is the single most effective tool for optimizing query performance in a relational database, but it requires strategic application to avoid negatively impacting write operations.
Actionable Tips for Implementation
To build an effective indexing strategy, consider these practical guidelines:
- Index High-Cardinality Columns: Prioritize indexing columns that are frequently used in
WHEREclauses and have a high number of unique values (high cardinality), such as user IDs or email addresses. - Create Composite Indexes: For queries that filter on multiple columns simultaneously, create a composite (or multi-column) index. The order of columns in the index is crucial; place the most selective column first.
- Avoid Over-Indexing: Do not index every column. Avoid indexing small tables where a full scan is already fast or columns that are frequently updated, as this can slow down write performance significantly.
- Monitor and Prune: Regularly use database monitoring tools to identify which indexes are being used and which are not. Remove unused indexes to reclaim space and reduce write overhead.
- Use Covering Indexes: For read-heavy queries, a covering index includes all the columns needed for a query. This allows the database to answer the query using only the index, without ever having to read the table data itself, resulting in a major performance boost.
3. Consistent Naming Conventions
Establishing and adhering to consistent naming conventions is a critical, yet often overlooked, discipline in database architecture. This practice involves creating a clear, predictable, and uniform system for naming all database objects, including tables, columns, indexes, stored procedures, and constraints. A well-defined convention acts as a common language for developers, making the schema self-documenting and significantly easier to understand. This organized approach is a fundamental component of effective database design best practices.
The core idea is to eliminate ambiguity and guesswork. When every developer knows that tables are plural and use snake_case (e.g., user_orders) while columns are singular (e.g., order_date), the entire development lifecycle becomes more efficient. This consistency reduces cognitive load, speeds up development, and simplifies the onboarding process for new team members, making the database far more maintainable in the long run.
Why It's a Best Practice
A database with inconsistent naming is chaotic and prone to errors. Imagine a schema where one table is named Customers, another tbl_Product, and a third ORDER_DETAILS. A developer would waste valuable time deciphering the structure instead of building features. By enforcing a standard, such as PostgreSQL's community preference for snake_case or Microsoft SQL Server's common use of PascalCase, you create a predictable and professional environment. This uniformity is crucial for team collaboration and long-term project health.
Key Insight: Naming conventions are not just about aesthetics; they are a form of communication. A consistent schema clearly communicates intent and relationships, reducing bugs and making the code that interacts with it cleaner and more intuitive.
Actionable Tips for Implementation
To implement robust naming conventions, establish clear rules and enforce them from day one:
- Choose a Case and Stick with It: Decide on one style for all objects, such as
snake_case(user_profiles),camelCase(userProfiles), orPascalCase(UserProfiles). Consistency here is more important than the specific choice. - Be Descriptive but Concise: Names should clearly convey purpose without being excessively long. For example, use
last_login_timestampinstead of a vague name likel_l_t. - Use Prefixes for Object Types: Consider using standard prefixes to identify object types at a glance, like
tbl_for tables,vw_for views,idx_for indexes, andfk_for foreign keys. - Document and Share: Create a formal naming convention document and make it a required part of your team's onboarding and code review process. This ensures everyone understands and follows the same rules.
4. Data Type Optimization
Data type optimization is the practice of selecting the most appropriate and efficient data types for each column in a database. This involves choosing a type that minimizes storage space, improves query performance, and maintains data integrity by accurately representing the data it holds. Instead of using generic or overly large data types, this approach tailors each column's type to its specific purpose, avoiding wasted resources.
Selecting the correct data type is a fundamental aspect of effective database design best practices. It directly impacts how much disk space your database consumes, how much memory it requires to process queries, and how quickly it can retrieve or manipulate data. A well-optimized schema with precise data types is faster, more efficient, and more scalable, preventing performance bottlenecks as the application grows.
Why It's a Best Practice
Choosing the right data types prevents a wide range of issues, from bloated databases to inaccurate calculations. For example, financial systems must use DECIMAL or NUMERIC types for monetary values to avoid the floating-point rounding errors inherent in FLOAT or REAL types. Similarly, an IoT application collecting sensor data can save terabytes of storage by using a SMALLINT for temperature readings that never exceed a certain range, rather than a standard INTEGER.
Key Insight: Data type optimization is a proactive performance tuning strategy. Getting it right during the design phase is far less costly and disruptive than trying to correct it after a database is already populated with millions of records.
Actionable Tips for Implementation
To implement data type optimization effectively, consider these guidelines:
- Use the Smallest Sufficient Type: Always select the smallest data type that can reliably accommodate all possible values for a column. For example, use
TINYINTfor a status flag that only has values from 0 to 255 instead of a fullINTEGER. - Choose
DECIMALfor Financial Data: Never useFLOATorREALfor monetary calculations. UseDECIMALorNUMERICto ensure precision and avoid rounding errors that can have serious financial implications. - Be Specific with Character Lengths: Avoid defining
VARCHARcolumns with maximum lengths likeVARCHAR(255)out of habit. Analyze the data and set a realistic length (e.g.,VARCHAR(50)for an email address) to optimize storage and memory usage. - Use Native Date/Time Types: Store dates and times using native types like
DATETIME,TIMESTAMP, orDATEinstead of strings. These types are more storage-efficient, support date-based calculations, and allow for proper indexing.
5. Referential Integrity with Foreign Keys
Referential integrity is a core concept that maintains consistency between related tables in a database. It ensures that relationships are valid and that actions on one table do not inadvertently corrupt data in another. This is primarily achieved through the use of foreign key constraints, which link a column in one table to the primary key of another, creating a dependable parent-child relationship between them. This structural enforcement is a critical component of robust database design best practices.
By defining these constraints, you essentially tell the database that a value in the child table (the foreign key) must correspond to an existing value in the parent table (the primary key). This prevents "orphaned" records, such as an order record that references a customer who no longer exists in the system. Enforcing these rules at the database level guarantees data consistency, regardless of the application logic built on top of it.
Why It's a Best Practice
A database with enforced referential integrity is fundamentally more reliable. In an e-commerce system, for example, a foreign key linking an Orders table to a Products table prevents an order from being created for a product that doesn't exist. It also dictates what happens if a product is deleted: should the corresponding orders be deleted as well, or should the deletion be blocked? This prevents data inconsistencies that are difficult and costly to fix later.
Key Insight: Referential integrity is the database's self-enforcing contract for data consistency. It shifts the burden of maintaining valid relationships from the application layer to the database itself, creating a more resilient and predictable system.
Actionable Tips for Implementation
To effectively implement referential integrity, consider the following guidelines:
- Always Define Foreign Keys: For any column that references another table's primary key, explicitly define a foreign key constraint. Don't rely on application logic alone to maintain these relationships.
- Choose Appropriate Cascade Options: Use
ON DELETEandON UPDATEactions (likeCASCADE,SET NULL, orRESTRICT) to define how the database should handle changes to a parent record. The choice depends entirely on your business rules. For example, deleting a customer mightCASCADEto delete their orders. - Index Foreign Key Columns: Most database systems do not automatically index foreign key columns. Adding an index can significantly improve the performance of join operations and lookups, which are common when working with related tables.
- Plan Deletion Strategies: Before implementing constraints, carefully plan how to handle the deletion of parent records. Blocking deletions (
RESTRICT) is often the safest default, but business logic may require a more complex strategy.
6. Database Documentation and Schema Versioning
Comprehensive database documentation and schema versioning are critical disciplines for maintaining the long-term health and usability of a database. This practice involves creating and maintaining a detailed record of the database structure, including table purposes, column definitions, relationships, and constraints. Paired with schema versioning, which tracks changes to the database structure over time, it provides a complete history of the database's evolution, which is a key element of effective database design best practices.
Just as source code for an application is versioned, the database schema should be treated with the same rigor. Schema versioning tools automate the process of applying and tracking database changes, ensuring that every environment (development, staging, production) is consistent and reproducible. This combination of documentation and versioning turns a potentially chaotic system into a predictable and manageable asset.
Why It's a Best Practice
A well-documented and version-controlled database is essential for team collaboration and system maintainability. For example, SaaS companies rely on tools like Liquibase or Flyway to manage schema changes across multiple customer instances, ensuring updates are applied reliably and without manual error. Similarly, in highly regulated industries like banking, detailed schema documentation is not just a best practice; it's a requirement for regulatory compliance, providing a clear audit trail of data structures and business rules.
Key Insight: Treating your database schema as code (Schema as Code) by versioning it alongside your application code is the most effective way to prevent environment drift and ensure reliable deployments.
Actionable Tips for Implementation
To implement robust documentation and versioning, follow these guidelines:
- Use Schema Versioning Tools: Adopt a dedicated tool like Flyway, Liquibase, or Alembic (for Python projects) to manage database migrations. These tools allow you to define schema changes in SQL or XML files that are version-controlled with your application.
- Generate Entity-Relationship Diagrams (ERDs): Use tools to automatically generate ERDs from your live database schema. This visual documentation provides an intuitive overview of table relationships and is much easier to keep up-to-date than manual diagrams.
- Document Business Logic: Clearly document not just what a column is (e.g.,
is_active), but why it exists. Explain the business rules, constraints, and any non-obvious logic associated with the data. This context is invaluable for future developers. Beyond just specific database documentation, understanding broader principles for effective software documentation best practices can significantly enhance your project's longevity. - Keep Documentation Close to Code: Store your documentation in your version control system (like Git) alongside the schema migration files and application code. This ensures it evolves with the system and is readily accessible to the entire team.
7. Security Best Practices
Database security encompasses a comprehensive set of measures to protect sensitive data from unauthorized access, breaches, and corruption. It involves a multi-layered approach that includes controlling who can access the data, what they can do with it, and ensuring its confidentiality and integrity. Integrating security from the initial design phase is not just an add-on; it's a fundamental component of effective database design best practices.
This process involves a combination of preventative and detective controls, from user authentication and authorization to encryption and activity monitoring. A secure database design anticipates potential threats and builds in defenses to protect its most valuable asset: the data. By treating security as a core requirement, you safeguard against financial loss, reputational damage, and regulatory penalties.
Why It's a Best Practice
A proactive approach to security is non-negotiable in today's data-driven world. For a healthcare system, this means implementing robust controls to maintain HIPAA compliance and protect patient privacy. Similarly, financial institutions rely on encryption and strict access controls to meet PCI DSS standards and secure customer transaction data. Failing to prioritize security can lead to catastrophic data breaches.
Key Insight: Security should be built into the database architecture from day one, not bolted on as an afterthought. A secure-by-design approach is far more effective and less costly than trying to fix vulnerabilities in a live system.
Actionable Tips for Implementation
To build a secure database, implement the following measures:
- Follow the Principle of Least Privilege: Grant users only the minimum permissions necessary to perform their job functions. A user who only needs to read data should not have write or delete privileges.
- Encrypt Data at Rest and in Transit: Use strong encryption algorithms to protect sensitive data stored in the database (at rest) and as it moves across the network (in transit). When considering data protection for your database, a key aspect involves choosing the right security methods, such as understanding encryption vs tokenization, to meet specific compliance and risk requirements.
- Use Parameterized Queries: Always use parameterized queries or prepared statements in your application code to prevent SQL injection attacks, one of the most common database vulnerabilities.
- Enforce Strong Authentication: Implement strong password policies and enable multi-factor authentication (MFA) for all database users, especially administrators.
- Maintain Audit Logs: Regularly monitor and log all database activity. These audit trails are crucial for detecting suspicious behavior, investigating security incidents, and meeting compliance requirements.
8. Performance Optimization and Query Design
Performance optimization and query design involve crafting efficient database queries and building schemas that enable high-speed data retrieval and manipulation. This discipline goes beyond just writing SQL that works; it requires understanding how the database engine executes requests, optimizing JOIN operations, using effective WHERE clauses, and designing tables and indexes to support an application's most frequent query patterns. This proactive approach is a critical component of modern database design best practices.

A well-designed schema can be severely hampered by poorly written queries. A single inefficient query can consume excessive server resources, leading to slow application response times and a poor user experience. By focusing on query performance from the start, developers ensure that the database can scale effectively as data volumes and user loads increase, preventing performance bottlenecks before they impact production systems.
Why It's a Best Practice
An optimized database responds quickly, providing a seamless experience for users. For example, a platform like Amazon must optimize its product search queries to return relevant results from billions of items in milliseconds. This is achieved not just through powerful hardware, but through intelligent query design, caching, and indexing strategies that minimize the work the database must do for each request.
Key Insight: Database performance is an integral part of application performance. Designing for efficient queries is not an afterthought; it's a core design principle that directly impacts scalability, user satisfaction, and operational costs.
Actionable Tips for Implementation
To implement performance optimization effectively, focus on these techniques:
- Analyze Query Execution Plans: Regularly use tools like
EXPLAIN(in SQL) to understand how the database is executing your queries. This reveals inefficiencies, such as full table scans where an index should be used, helping you pinpoint optimization opportunities. - Avoid
SELECT *in Production: Always specify the exact columns you need. Pulling unnecessary data increases network traffic, memory usage, and processing overhead for both the database and the application. - Optimize
WHEREClauses andJOINs: Ensure that columns used inWHEREclauses, especially in large tables, are properly indexed. Use the most appropriateJOINtype (e.g.,INNER JOINvs.LEFT JOIN) and understand how the order of joined tables can impact performance. - Consider Query Caching: For frequently accessed, static data, implement a caching layer. This allows you to serve results from memory instead of repeatedly querying the database, drastically reducing response times and database load.
Best Practices Comparison of 8 Database Design Principles
| Topic | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Database Normalization | Medium to High – Requires understanding normal forms and schema design | Moderate – May increase CPU for joins | Improved data integrity and reduced redundancy | OLTP systems, transactional databases | Ensures data consistency and reduces anomalies |
| Proper Indexing Strategy | Medium – Requires knowledge of index types and query patterns | Moderate to High – Extra storage and maintenance | Faster data retrieval and query performance | Read-heavy systems, complex queries | Dramatically improves query speed |
| Consistent Naming Conventions | Low to Medium – Establishing and enforcing standards | Low – Mainly documentation effort | Better readability and maintainability | Team environments, long-term projects | Standardizes schema for easier collaboration |
| Data Type Optimization | Medium – Careful data analysis needed | Low to Moderate – Storage optimization | Reduced storage, improved accuracy | High-volume systems, storage-sensitive apps | Saves space and improves performance |
| Referential Integrity with Foreign Keys | Medium – Defining constraints and cascade rules | Moderate – Slight performance cost on updates | Maintains relational data consistency | Systems with complex relationships | Prevents orphan records and enforces rules |
| Database Documentation & Schema Versioning | Medium to High – Ongoing documentation and version control | Moderate – Time and tooling investment | Easier maintenance and compliance | Large teams, regulated industries | Enhances collaboration and auditability |
| Security Best Practices | Medium to High – Requires careful policy and tool implementation | Moderate to High – Security tools and monitoring | Protects data integrity and privacy | Regulated industries, sensitive data handling | Ensures compliance and prevents breaches |
| Performance Optimization & Query Design | High – Deep understanding of query internals and schema tuning | Moderate – Monitoring and tuning tools | Faster response and lower resource use | High-traffic, large-scale applications | Improves scalability and reduces costs |
From Theory to Practice: Building Your Future-Proof Database
Navigating the landscape of database design can feel like assembling a complex puzzle. Each piece, from the granular choice of a data type to the overarching security strategy, plays a critical role in the final picture. Throughout this guide, we've explored eight foundational pillars that transform a functional database into a high-performance, scalable, and secure asset for your organization. By internalizing these database design best practices, you move beyond simply storing data and begin architecting a true system of record that drives business value.
The journey starts with the logical structure. Normalization is not just an academic exercise; it's the very blueprint for data integrity, preventing redundancy and ensuring that your data remains consistent and reliable as it grows. Complementing this is a robust indexing strategy, which acts as the high-speed navigation system for your data, turning sluggish queries into instantaneous responses that enhance user experience and application performance.
Weaving the Practices Together for a Cohesive Strategy
Consistency and clarity are the threads that tie a well-designed database together. Adhering to strict naming conventions and optimizing data types may seem like minor details, but their cumulative impact is immense. They create a self-documenting system that is easier for new developers to understand, simpler to maintain, and less prone to costly errors. This clarity is reinforced by establishing referential integrity with foreign keys, which builds a resilient relational structure that mirrors your real-world business rules.
However, a perfectly structured database is incomplete without a plan for its evolution and protection. Comprehensive documentation and schema versioning provide a historical record and a roadmap for future changes, preventing technical debt and facilitating collaboration. Simultaneously, embedding security best practices from the very beginning, like implementing the principle of least privilege, is non-negotiable. It fortifies your most valuable asset against threats and ensures you meet compliance standards.
From Proactive Design to Long-Term Success
Ultimately, the goal of applying these principles is to achieve sustained performance optimization. A database designed with best practices in mind is inherently faster, more efficient, and more scalable. It empowers you to build applications that can handle increased load, support complex business logic, and adapt to changing requirements without requiring a complete overhaul.
Think of these eight principles not as a checklist to be completed once, but as a continuous cycle of refinement. As your application evolves, you will revisit your indexing, adjust your security protocols, and update your documentation. Mastering these database design best practices is an ongoing commitment to quality and foresight. It's an investment that pays dividends in reduced maintenance costs, improved application stability, and the agility to innovate with confidence. Your database is the heart of your digital operations; building it with expertise ensures it will beat strongly for years to come.
Ready to transform your theoretical knowledge into a tangible, high-performance database solution? The expert team at KP Infotech specializes in architecting and implementing robust data infrastructures that power growth and innovation. Let's build your future-proof database together.