

Combining SQL COUNT() with GROUP BY is how you turn massive tables of raw data into tidy, meaningful summaries. Instead of just getting a single, total count of all the rows, this powerful duo lets you count items within specific categories. It’s the go-to technique for answering everyday business questions like, "How many orders has each customer placed?" or "How many employees work in each department?"
Why SQL Count Group Is Your Data Analysis Superpower

Let’s be real—raw data is just a wall of noise until you can make sense of it. This is exactly where combining COUNT() with GROUP BY becomes an absolute game-changer. It’s the fundamental tool for transforming messy, sprawling datasets into clear, actionable intelligence.
Forget about simple row counts. We're talking about digging up genuine business insights. Imagine being able to see, in seconds, which marketing campaigns are driving the most sign-ups, or pinpointing your top-selling products by region. This isn't just a technical skill; it's the bedrock of smart, strategic decision-making.
From Raw Data to Clear Insights
The whole point of using sql count group is to get past a flat, one-dimensional list of records. You're essentially telling the database to sort your data into buckets first, and then count the items inside each one. This simple action allows you to:
- Spot Trends: See which product categories are flying off the shelves or which cities have the most active customers.
- Measure Engagement: Count user activities, like how many comments each person has left on your blog.
- Monitor Operations: Keep tabs on the number of support tickets assigned to each agent or the daily transaction volume.
This capability is so foundational that it’s used everywhere, across every industry. In Russia, for example, sectors like finance and telecommunications rely heavily on this combination for daily reporting. Banking institutions processing millions of transactions a day use COUNT with GROUP BY to summarise transaction volumes by branch or region. In fact, a 2022 report pointed out that for over 70% of large enterprises, these types of aggregation queries make up 30-40% of their entire analytical workload. You can learn more about these powerful SQL functions and their applications.
Key Takeaway: Using
COUNT()withGROUP BYisn't just about counting. It's about structuring information to uncover patterns and answer specific business questions that a simple total count could never hope to address.
Ultimately, mastering this query structure is a non-negotiable step in graduating from basic data retrieval to genuine data analysis. The insights you pull can directly shape business strategy, making it a true superpower in any data-focused role. And once you have those insights, understanding the principles of analytics and data visualization is the perfect next step to present your findings effectively.
Decoding the COUNT and GROUP BY Syntax

Writing your first query combining COUNT with GROUP BY can feel a bit strange, but it follows a really logical structure. Once you get the hang of it, you'll see it everywhere. Let's break down the syntax piece by piece so you can see exactly how it works.
The basic query structure is always the same. You SELECT your columns, tell the database which table to pull FROM, and then use GROUP BY on the column you want to use for categorising your counts.
SELECT
column_to_group_by,
COUNT(*)
FROM
your_table
GROUP BY
column_to_group_by;
This simple template is the workhorse of so many data analysis tasks. It tells the database to first organise all the rows into separate buckets based on the values in column_to_group_by. Then, it just counts the number of rows that landed in each bucket. Simple as that.
Unpacking the COUNT Function Variations
One of the first things that trips people up is what to put inside the COUNT() parentheses. While COUNT(*) is what you'll see most often, there are subtle but important differences between the main options.
COUNT(*): This is the most straightforward option. It counts all rows within each group, and it doesn't care if some columns haveNULLvalues.COUNT(column_name): This version counts the number of rows where the specificcolumn_namehas a non-NULL value. It's perfect when you only want to tally records that actually have data in a particular field.COUNT(DISTINCT column_name): This one is for counting only the unique non-NULL values in a column within each group. For instance, you could use it to count how many distinct products were sold in each region, even if the same product was sold multiple times.
Picking the right one really just depends on the question you're asking. Do you need a headcount of all records, or only the ones with specific data points? Getting this right is crucial for accurate analysis.
The Golden Rule of Grouping: Any column in your
SELECTlist that isn't wrapped in an aggregate function (likeCOUNT(),SUM(), orAVG()) must also be in yourGROUP BYclause. Forgetting this is probably the most common error beginners run into.
A Practical Example with an Orders Table
Let's make this real. Imagine you have a simple orders table with columns like order_id, customer_id, and order_date. If you want to find out how many orders each customer has placed, your query would look like this:
SELECT
customer_id,
COUNT(order_id) AS total_orders
FROM
orders
GROUP BY
customer_id;
Here, we're grouping all the rows by customer_id and then counting the order_ids for each one. The result is a clean summary showing each customer and their total order count.
Of course, before you can run complex counts, you often need to pull information from multiple places. You might need customer names from a customers table and their order details from the orders table. For that, you absolutely need to understand how to join two tables in SQL, as it's a foundational skill for most real-world grouping scenarios.
Putting Theory into Practice with Real Scenarios

It’s one thing to memorise syntax, but the real magic of SQL COUNT() with GROUP BY happens when you use it to solve actual business problems. Let's move past the textbook theory and get our hands dirty with a couple of practical scenarios you’d likely run into in any e-commerce or content management job.
This isn’t just for practice; it’s a core skill. Data analytics is more important than ever, and these SQL functions are front and centre. A 2023 survey of 150 Russian universities found that 82% now include practical SQL exercises focused on aggregate functions and grouping. This lines up perfectly with a 45% jump in job postings that list SQL proficiency as a must-have skill.
Scenario One: Counting Orders per Customer
Let’s kick things off with a classic e-commerce question: "How many orders has each customer placed?" This is a fundamental metric for spotting your most loyal customers—the ones who keep coming back.
Imagine you're working with an orders table that looks something like this:
| order_id | customer_id | order_date | order_total |
|---|---|---|---|
| 101 | 55 | 2023-11-10 | 49.99 |
| 102 | 82 | 2023-11-10 | 112.50 |
| 103 | 55 | 2023-11-12 | 75.00 |
| 104 | 91 | 2023-11-12 | 24.99 |
| 105 | 55 | 2023-11-15 | 89.99 |
To get the answer, you need to group all the records by customer_id and then just count the orders inside each group. Simple.
SELECT
customer_id,
COUNT(order_id) AS number_of_orders
FROM
orders
GROUP BY
customer_id
ORDER BY
number_of_orders DESC;
When you run this, you get a tidy summary. You’d see that customer 55 has a number_of_orders count of 3, while customers 82 and 91 each have a count of 1. I threw in an ORDER BY clause, too—it’s a nice little touch that puts your top customers right at the top of the list for quick analysis.
Scenario Two: Analysing Content by Category
Now, let's pivot to a content-focused example. Say you manage a blog and want to figure out which topics your writers are gravitating towards. Your articles table might be structured like this:
| article_id | title | author_id | category | publish_date |
|---|---|---|---|---|
| 501 | Getting Started with SQL | 12 | Tech | 2023-10-01 |
| 502 | Healthy Eating Tips | 7 | Wellness | 2023-10-05 |
| 503 | Advanced SQL Joins | 12 | Tech | 2023-10-15 |
| 504 | Morning Yoga Routines | 7 | Wellness | 2023-10-20 |
| 505 | Database Normalisation | 12 | Tech | 2023-11-01 |
The business question here is straightforward: "How many articles have we published in each category?" The COUNT and GROUP BY combination is perfect for this.
SELECT
category,
COUNT(*) AS article_count
FROM
articles
GROUP BY
category;
This simple query gives you an instant, high-level snapshot of your content strategy. You’d immediately see that the 'Tech' category has 3 articles and 'Wellness' has 2. This helps you spot where your content is concentrated and where you might have gaps.
Getting these numbers is powerful, but their real value comes alive when you can present them clearly. For some great tips on turning raw data into compelling charts and dashboards, take a look at our guide on https://kpinfo.tech/data-visualization-best-practices/. When you can visualise the data, you can start asking—and answering—much smarter questions.
Filtering Your Groups with the HAVING Clause
Grouping your data with COUNT is a great start, but the real power comes when you start filtering those groups. What if you only want to see categories with more than 10 products? Or customers who have purchased at least five times? This is precisely what the HAVING clause was built for.
A lot of people get HAVING mixed up with the WHERE clause, but their jobs are completely different. The easiest way to think about it is as a two-step filtering process:
- The
WHEREclause filters individual rows before any grouping or aggregation happens. - The
HAVINGclause filters the aggregated groups after theCOUNT()function has already done its work.
This separation is crucial. You can't use WHERE to filter on an aggregate function like COUNT() because, at the moment WHERE is evaluated, the count simply doesn't exist yet. HAVING is your tool for querying the results of your aggregations.
The Key Difference: WHERE vs. HAVING
Let's make this crystal clear. Imagine you want to find customers from London who have placed more than two orders. This is a perfect scenario where you need both WHERE and HAVING.
Here’s how you’d write the query:
SELECT
customer_id,
COUNT(order_id) AS total_orders
FROM
orders
WHERE
city = 'London'
GROUP BY
customer_id
HAVING
COUNT(order_id) > 2;
First, WHERE city = 'London' throws out all the individual order rows that aren't from London. Then, GROUP BY and COUNT() get to work on what's left. Finally, HAVING COUNT(order_id) > 2 filters those resulting groups, leaving you with only the London customers who have more than two orders.
Pro Tip: A simple way to remember the difference is that
WHEREacts on rows, andHAVINGacts on groups. You applyHAVINGto the final summarised output of yourGROUP BYclause.
To bring this all together, it's helpful to see a clear side-by-side comparison.
WHERE vs HAVING Clause Comparison
| Characteristic | WHERE Clause | HAVING Clause |
|---|---|---|
| Purpose | Filters individual rows from a table. | Filters groups created by the GROUP BY clause. |
| Timing of Execution | Executed before grouping and aggregation. | Executed after grouping and aggregation. |
| Use with Aggregates | Cannot be used with aggregate functions like COUNT(), SUM(). | Specifically designed to be used with aggregate functions. |
| Typical Placement | Appears before the GROUP BY clause. | Appears after the GROUP BY clause. |
| Example Scenario | Selecting all orders placed in 'London'. | Finding customers in 'London' who have more than 2 orders. |
This table neatly sums up the distinct roles these two clauses play in crafting your SQL queries.
Filtering large, grouped datasets can be slow, but simple optimisations can make a huge difference. The chart below shows just how much impact a single index can have on performance.
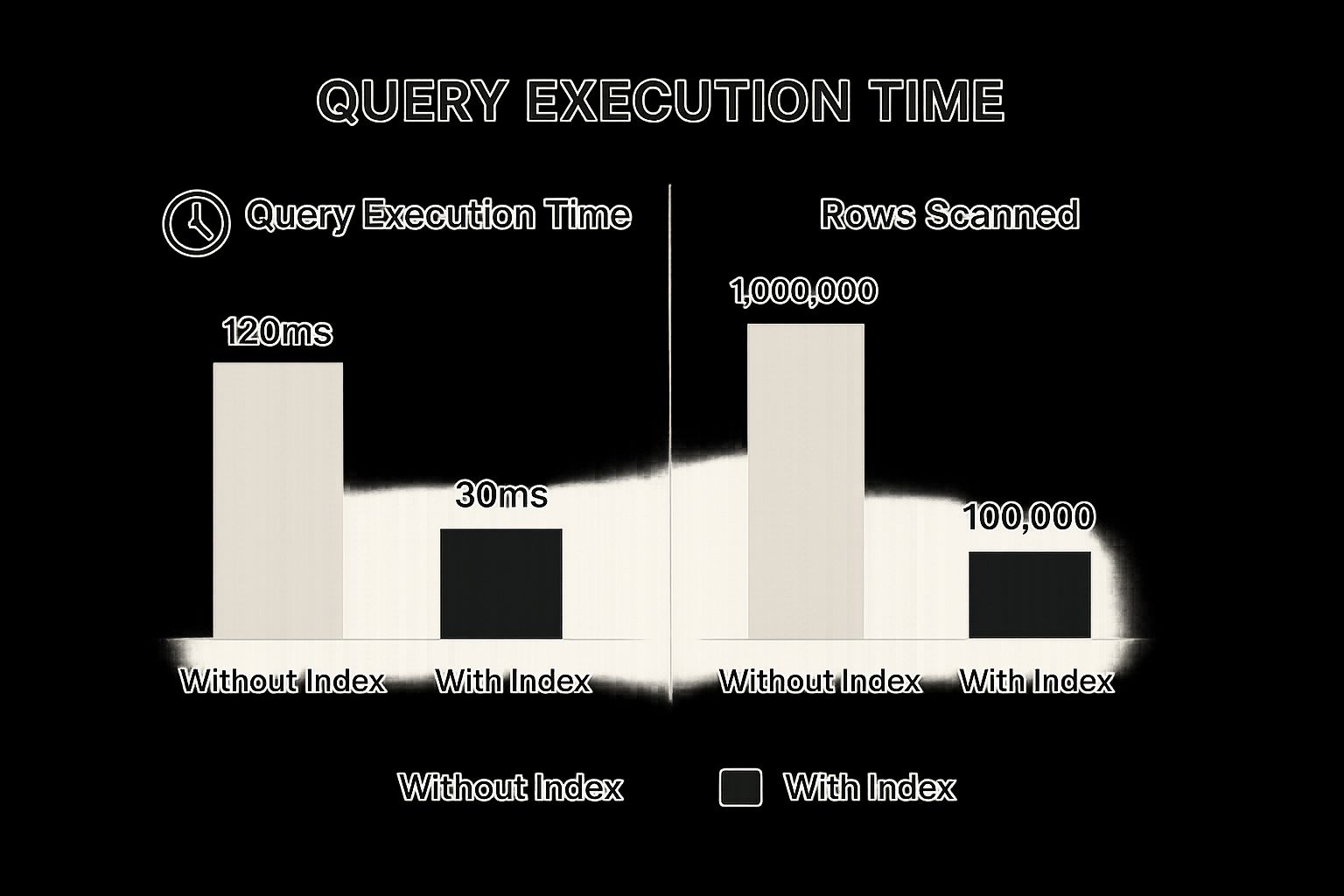
This visualisation shows that indexing can slash query execution time by 75% and reduce the number of rows scanned by a massive 90%, making your filtering operations much, much faster.
Practical Use Cases for HAVING
Once you get the hang of it, you'll find endless uses for filtering your grouped results. It elevates your analysis from simple summaries to genuinely targeted insights.
Here are just a few real-world scenarios where HAVING really shines:
- Identifying Power Users: Find users who have posted more than 50 comments.
- Inventory Management: Show product categories that have fewer than 10 items left in stock.
- Sales Analysis: List sales representatives who closed more than 20 deals last quarter.
- Geographic Targeting: Pinpoint cities with over 1,000 active customers to plan a new marketing campaign.
Each of these questions requires you to first group and count the data, then apply a condition to that final count. This makes HAVING an indispensable tool for anyone doing serious data analysis.
Advanced Grouping and Performance Tips
You've got the basics of SQL COUNT() with GROUP BY down, and that's a huge step. But the real magic happens when you start layering in more complex logic and, crucially, making sure your queries don't grind to a halt on massive datasets.
Let's dig into a few techniques that will take your data grouping skills from good to indispensable.
Grouping by Multiple Columns
Sometimes, a single GROUP BY just doesn't cut it. You need more detail. A common scenario is needing counts broken down by multiple criteria at the same time, and you can do this without writing a bunch of separate queries.
Imagine you're trying to figure out how many orders each customer places every month. This is a classic business question that requires you to group your data by both the customer and the specific month of their order. By simply adding more columns to your GROUP BY clause, you can create these multi-level summaries in one go.
For example, if you have an orders table, your query could look something like this:
SELECT
customer_id,
EXTRACT(YEAR FROM order_date) AS order_year,
EXTRACT(MONTH FROM order_date) AS order_month,
COUNT(order_id) AS monthly_orders
FROM
orders
GROUP BY
customer_id,
order_year,
order_month
ORDER BY
customer_id,
order_year,
order_month;
This query slices the data with surgical precision. Instead of just a total order count per customer, you get a clear picture of their purchasing frequency over time—a much richer insight for spotting trends.
Conditional Counts with CASE Statements
What if you need to count different types of things within the same group? For example, let's say for each product category, you want to see a count of "shipped" orders right next to a count of "pending" orders.
This is where a CASE statement inside your COUNT() function becomes your best friend. This technique is incredibly efficient, letting you build out pivot-table-style summaries in a single pass over the data.
Key Insight: Combining
COUNTwithCASEis a game-changer. It stops you from having to run multiple queries or build complicated joins for conditional counting. You can slice and dice your counts right inside each group, making your SQL cleaner and a whole lot faster.
Optimising for Performance
When your tables start getting seriously large, GROUP BY operations can become painfully slow. The single most effective thing you can do to speed them up is to index the columns you are grouping by.
An index acts like a super-fast table of contents, helping the database engine find and organise the rows for each group without having to scan the entire table from top to bottom. A solid schema is the foundation for all of this; you can get a deeper understanding of structuring your tables with these database design best practices.
Without the right indexes in place, a query that takes minutes to run on a large dataset could potentially finish in just a few seconds.
For situations with truly massive datasets and complex groupings, it's also worth looking into advanced data handling techniques like flawless data pagination. This helps you manage huge result sets without overwhelming your system.
Common Questions About SQL Count Group
When you're working with COUNT() and GROUP BY, a few questions almost always come up. It's totally normal. Let's walk through some of the most common sticking points to get you writing cleaner, more efficient queries right away.
COUNT(*) vs. COUNT(1) – Which One Wins?
This is probably the most common point of confusion. The short answer? It doesn't matter.
For all practical purposes, COUNT(*) and COUNT(1) are identical in performance and result. Both tell the database to simply count all the rows in each group. The query optimiser is smart enough to see them as the same instruction.
My advice? Pick the one you find easier to read and stick with it. Consistency is key.
Can I Group By a Column That Isn't in My SELECT List?
Another great question. The answer is yes, you absolutely can.
It’s definitely common practice to include the GROUP BY column in your SELECT statement—it usually makes the results easier to understand. But it's not a technical requirement. You might just want a raw count of employees in each department without needing the department names cluttering up your output. Go for it.
How Do I Handle NULL Values?
Ah, NULLs. They can throw a spanner in the works if you’re not paying attention. It all comes down to understanding how the different COUNT variations see them.
Here's the breakdown:
COUNT(*): This is the most straightforward. It counts every single row in a group, period. It doesn't care if columns areNULL.COUNT(column_name): This one is more specific. It only counts rows wherecolumn_nameactually has a value (i.e., it's notNULL). If your counts seem low, this is often the culprit.COUNT(DISTINCT column_name): Just like the one above, but it only counts the unique non-NULL values in that column.
What if you want to treat
NULLas its own category? Good news—theGROUP BYclause does this for you automatically. It will lump all rows with aNULLin the grouping column into their own group and give you a count for it.
Finally, a quick tip on ordering your results. You can definitely sort by your aggregated count, but make sure to use the column alias you created (e.g., ORDER BY total_orders DESC). It keeps your query tidy and is even required by some database systems. Getting these little details right will make troubleshooting much faster and help you build rock-solid queries from the start.
At KP Infotech, we turn complex data challenges into clear business solutions. Whether you need a high-performance website, a custom web application, or expert ERP implementation, our team is ready to help you grow. Learn more about our services at https://kpinfo.tech.